研究開発本部の山本です。前回はフリーの解析サービスであるMetaboAnalystを用いてオミクスデータに対して主成分分析を行う具体的な手順についてご説明しました。
今回は前回省略した欠損値補完とスケーリング、主成分分析の結果の解釈についてご説明したいと思います。
■Missing Value Estimation
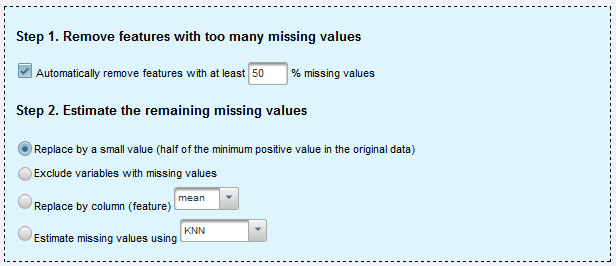
Missing value estimationでは欠損値の補完を行います。
ある代謝物質がサンプルによって検出されたりされなかったりした場合などに欠損値が生じます。MetaboAnalystでは代謝物質ごとに欠損値の割合を調べて、その割合が多いピークは削除する、欠損値は最小値の半分で補完する等、様々な方法が実装されています。
欠損値の補完には決まったルールはありませんが、データセットに欠損値があると主成分分析が計算出来ないので、欠損値には何らかの値を埋める必要があります。
■Sample Normalization
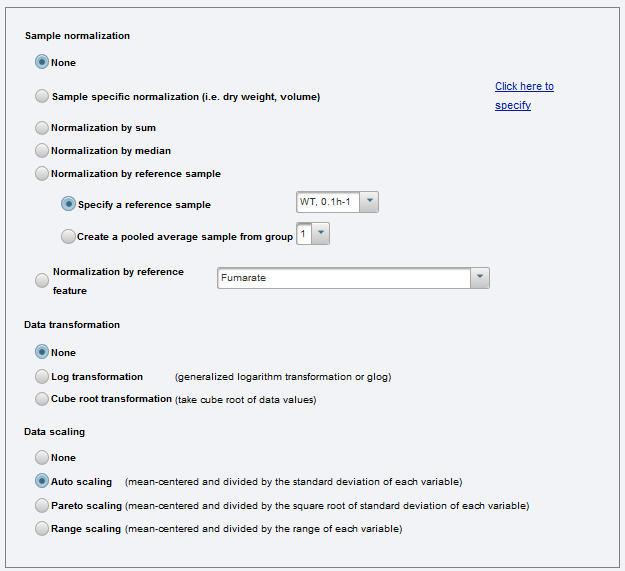
Sample normalizationは乾燥重量などの補正が必要な値や、基準となるサンプルで補正したい時などに用い、Data transformationは代謝物質ごとに対数変換などの処理を行うことができます。
ただし、メタボロームデータに主成分分析を行うほとんどの場合は、変換してしまうと解析後の結果と元のデータの様子が合わなくなることが多いので、特別な理由がある時以外はこれらの変換は考えなくても良いでしょう。
■Data Scaling
Data scalingは非常に重要です。
MetaboAnalystでは、Auto scaling、Pareto scaling、Range scalingの3つの方法が用意されています。Auto Scalingは各代謝物質ごとにその代謝物レベルを平均0、分散1に変換するもので、基本的にはAuto scalingがおすすめです。
Auto scalingは全ての代謝物質をそれぞれ平均0、分散1に変換してしまうので、絶対定量値が得られている場合など各代謝物質の大きさを反映させたい場合には、スケーリングなしまたは各代謝物質の大きさがAuto scalingよりも反映されるPareto scalingが用いられることもあります。
ただし、メタボロームデータに主成分分析する目的は「全体の傾向を視覚的に表したい」ことがほとんどだと思いますので、スケーリングを行わなわなかった場合、分散が大きい代謝物質の影響を受けて必ずしもメタボロームデータ全体の傾向を表さないことには注意してください。
■主成分分析の結果の読み取り-スコアプロット
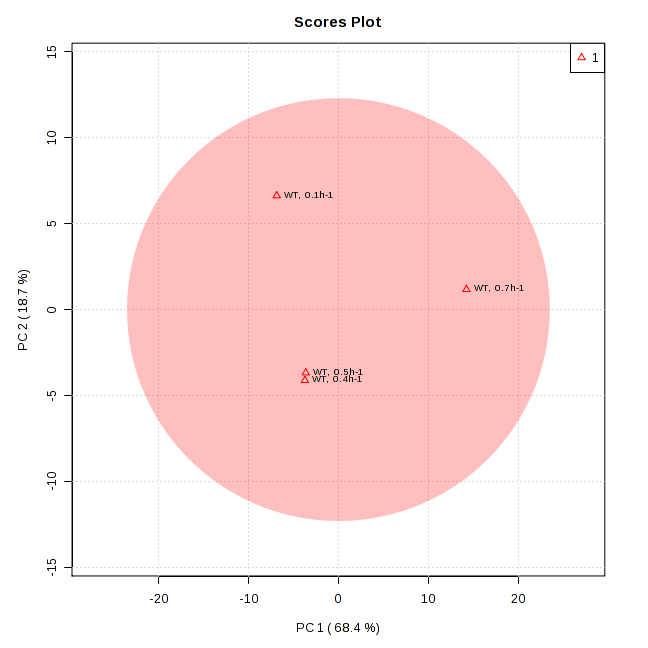
左図は、慶應義塾大学の大腸菌メタボロームデータのうち、異なる4つの増殖速度(0.1h-1, 0.4h-1, 0.5h-1, 0.7h-1)での大腸菌のメタボロームデータに限定して主成分分析を行い、得られた主成分スコアプロットです。
欠損値補完とデータ変換はdefaultの設定のまま、Data scaling はAuto scalingを行った後、主成分分析を行いました。
第一主成分(PC1)のスコアは、小さい方から
0.1h-1→(0.4h-1/0.5h-1)→0.7h-1
の順に並び、第二主成分(PC2)のスコアは、小さい方から
(0.4h-1/0.5h-1)→0.7h-1→0.1h-1
の順に並んでいることが分かります。
横軸と縦軸のラベルに記されているパーセンテージ(68.4%、18.7%)は「寄与率」です。寄与率とは各主成分スコアの分散の和に対するそれぞれの主成分の分散の比です。
今回の設定から読み取れることとしては、「第一主成分の寄与率が高い(68.4%)ので第一主成分スコアと同じような傾向を示す代謝物質が多く、第二主成分の寄与率が低い(18.7%)ので第二主成分スコアと同じような傾向を示す代謝物質は相対的に少ない」と言えます。
つまりこの図からは、「第一主成分スコアが増殖速度の順に並んでいてかつ寄与率も高いことから、多くの代謝物質が増殖速度に関連して変動している」ということが読み取れます。
■主成分分析の結果の読み取り-ローディングプロット
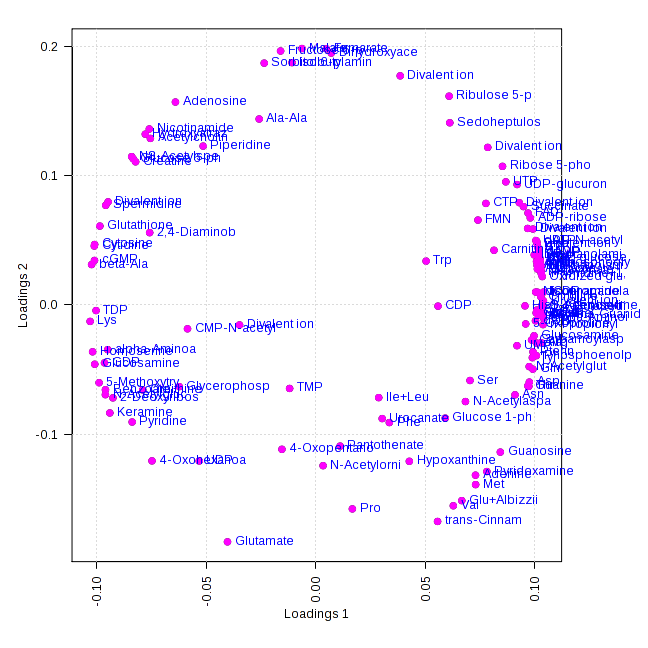
第一主成分スコアは小さい方から0.1h-1→(0.4h-1/0.5h-1)→0.7h-1の順に並んでいたので、
ローディングの値が正に高いものは、第一主成分スコアの0.1h-1→(0.4h-1, 0.5h-1)→0.7h-1の順番で上昇するパターンを示す代謝物質
ローディングの値が負に高いものは、0.1h-1→(0.4h-1, 0.5h-1)→0.7h-1の順番で低下するパターンを示す代謝物質
となります。
このように、主成分スコアとローディングはセットで見る必要があります。同じデータであっても、ソフトウェアや計算のアルゴリズムによって主成分スコアは正負逆になることがありますが、スコアとローディングをセットで見ていれば問題ありません。
また説明のしやすさ等の理由から、スコアプロットを正負逆にしても問題ありません。その場合は対応する主成分のローディングの正負も同じく逆にするのを忘れないようにしてください。
主成分分析からの結果の解釈の流れをまとめると、
- まずそれぞれご自身の研究の興味にあったパターンが主成分スコアに表れているかを確認し(今回の場合では大腸菌の増殖速度)
- 興味深いパターンを示す主成分スコアが見つかった場合には、対応するローディングを確認し代謝物質を選択
- さらに生物学的な解釈を進めていく
という流れになります。
メタブローグをご覧の方々は、統計解析を専門でご研究されているわけではないと思いますので、今回ご紹介した部分までご理解いただいていれば、主成分分析については十分だと思います。
今回はMetaboAnalystを用いた主成分分析の結果の解釈についてご説明してきましたが、主成分分析のローディングは、ソフトウェアによって定義が異なっていることから、異なる値が得られることがあります。次回は、この点についてご説明したいと思います。