研究開発本部の山本です。前篇では、実は「ローディング」と言われているものの定義が場合によって異なり、因子負荷量をデータの解釈に使用する場合は相関係数として取り扱うと解釈しやすいというお話をしました。
今回は実際に、MetaboAnalystの因子負荷量の結果と、相関係数で定義される因子負荷量の結果を比較してみましょう。
データは第4回で使用したのと同じ、異なる増殖速度での大腸菌のメタボロームデータを用います。
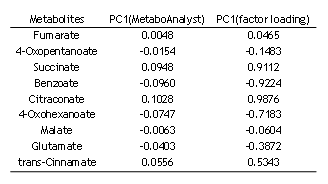 左の表は、1列目に代謝物名、2列目にMetaboAnalystで得られたPC1のloading、3列目にPC1のfactor loading(PC1のスコアと各代謝物質の相関係数)の抜粋です。
左の表は、1列目に代謝物名、2列目にMetaboAnalystで得られたPC1のloading、3列目にPC1のfactor loading(PC1のスコアと各代謝物質の相関係数)の抜粋です。
その値を見ると、PC1(factor loading)はPC1(MetaboAnalyst)の約10倍(10.04倍)になっています。このことは、先述したように固有ベクトルと、PC1のスコアと各代謝物質レベルとの相関係数が比例することを示しています。
これまでの因子負荷量の使われ方は、PC1(MetaboAnalyst)の上位X個(X個の選択に理由はない)の物質に注目する、といったものが多かったと思います。
例えばPC1(MetaboAnalyst)の値を見て上位10個を選ぶとします。試験Aでは全部相関係数が0.9以上で、試験Bでは10個中1個だけ相関係数が0.9で、
残りの9個は相関係数が0.5ということもありえます。この場合、同じように上位10個が選ばれてしまっていますが、試験Aは10個(かそれ以上)の代謝物質を見て解釈をした方が良いですし、試験Bは相関が高かった1個の代謝物質についてのみ解釈するのが自然かと思います。
PC1(MetaboAnalyst)の値を使用する場合でも、相関係数と比例した値であるということを念頭において利用されると良いのではないでしょうか。
測定データをさらに生物学的な解釈へと繋げていくためには、3列目のPC1(factor loading)である相関係数を用い、例えば0.7以上の代謝物質を選択しそれらの物質について生物学的な解釈を行う、といった方法が望ましいです。また、より統計的に裏付けのある選択をするため、因子負荷量の仮設検定を行おうとした場合、その値は相関係数になっている必要がありますのでご注意ください。
因子負荷量の定義はソフトウェアによって異なると思いますので、お手元のソフトウェアで一度ご確認いただければと思います。
上記の通り、MetaboAnalystの場合は、loadingは固有ベクトルになっていますので、別途Microsoft Excelなどで主成分スコアと各代謝物質レベルの相関係数(関数:correl)を計算し、その値を因子負荷量とすることを勧めします。IBM社のSPSSで因子負荷量を計算した場合には、最初から相関係数になっているので、そのままお使いいただけます。
次回は、さらに因子負荷量から統計的な基準で代謝物質を選択するために、因子負荷量の仮説検定の方法についてご紹介したいと思います。