解析手法の紹介
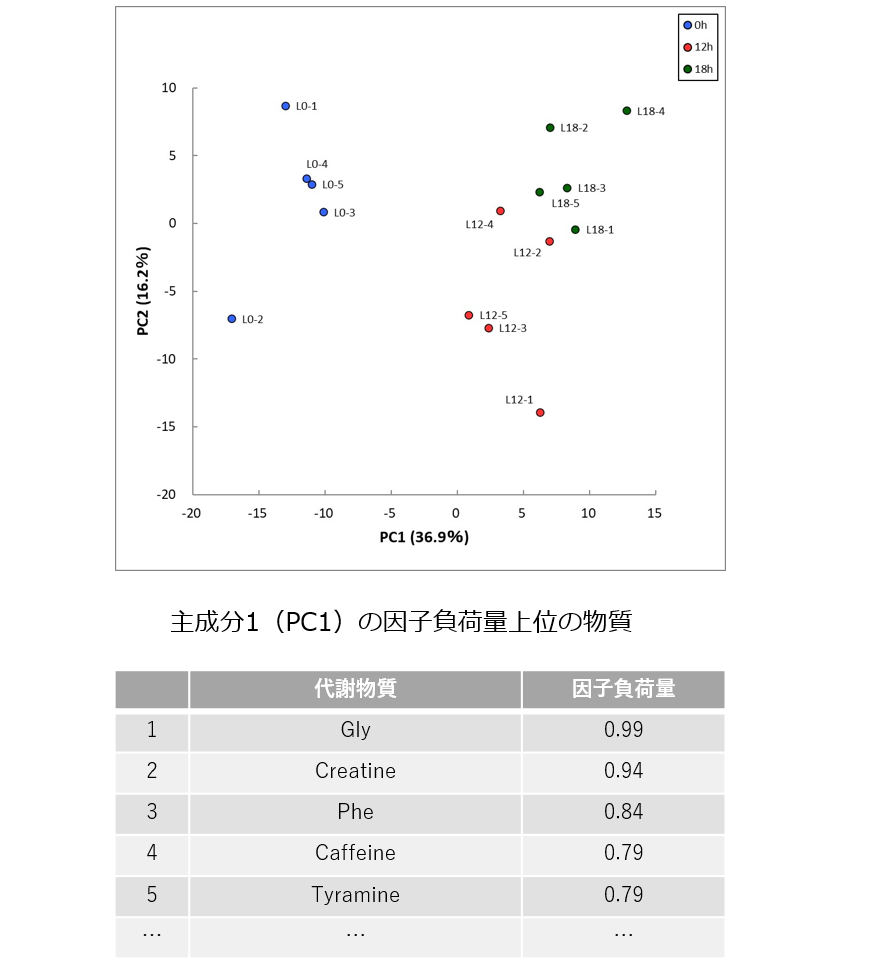
主成分分析(Principal component analysis, PCA)
主成分分析(PCA)は、得られたデータが全体的にどのような傾向を示すのか、時系列や群情報が確認出来るかどうかを知るために用いられます。
代謝物質の数だけ存在するデータの次元を縮約し、少数の新しい次元をもつデータに置き換えることで、データの特徴を捉えやすくすることが可能です。
また、データを可視化すると同時に、特徴的な代謝物質群(重要物質群)を抽出することができるので、メタボローム解析をもとにその後の生物学的な解釈を行う上では非常に重要な役割を果たします。
その結果、視覚的にわかりやすい主成分分析のプロットを確認することで、サンプルや群同士がどのくらい似ているか(あるいは異なるか)がわかるとともに、差異の原因となる代謝物質の候補も探索することが可能となります。
※HMTのメタボローム解析プランにおいてPCAとHCAは標準で報告書に付属します。
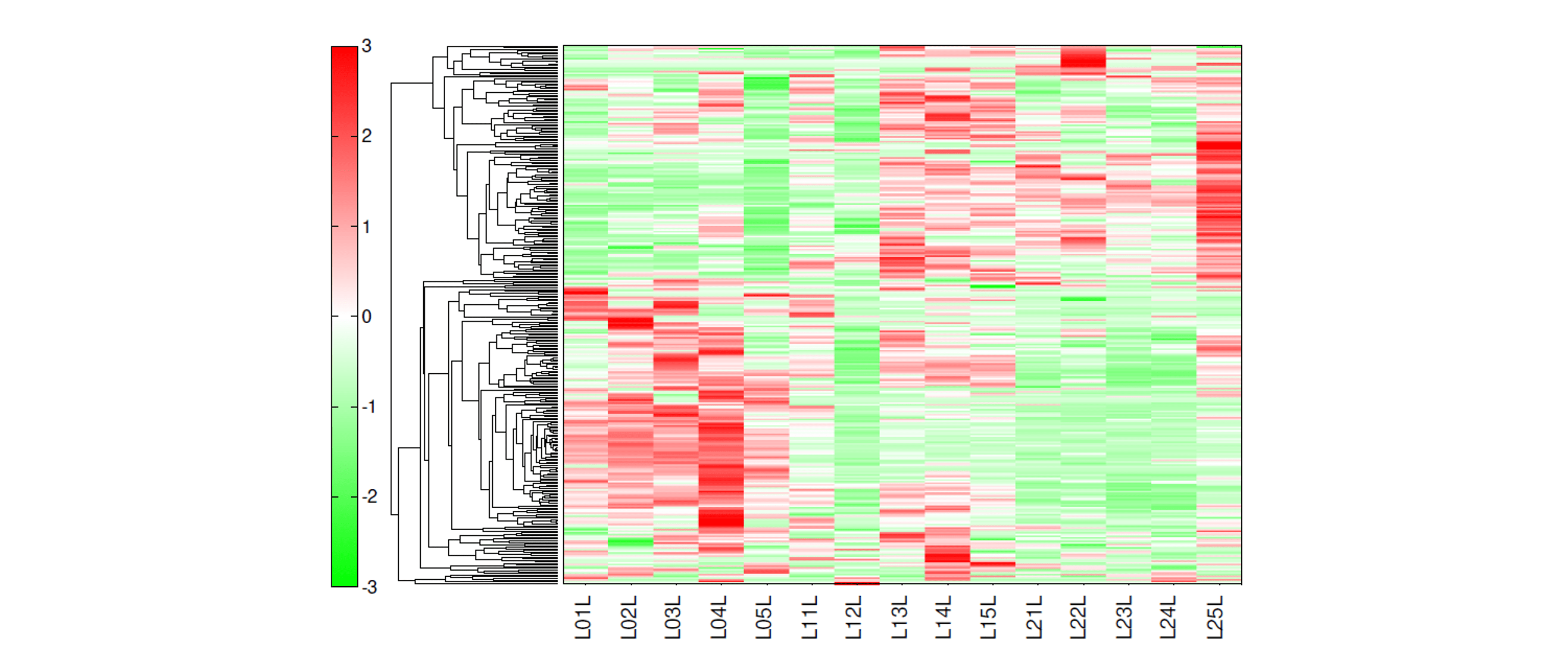
階層的クラスタリング解析(Hierarchical clustering analysis, HCA)
階層的クラスタリング解析(HCA)は、それぞれの代謝物質のプロファイルの類似性を基準にグループ分けを行う(クラスタリング)多変量解析手法の一種です。
各検体における代謝物質の値が平均値より高値であれば濃い赤色で、低値であれば濃い緑色で表示されます(ヒートマップ)。
※HMTのメタボローム解析プランにおいてPCAとHCAは標準で報告書に付属します。
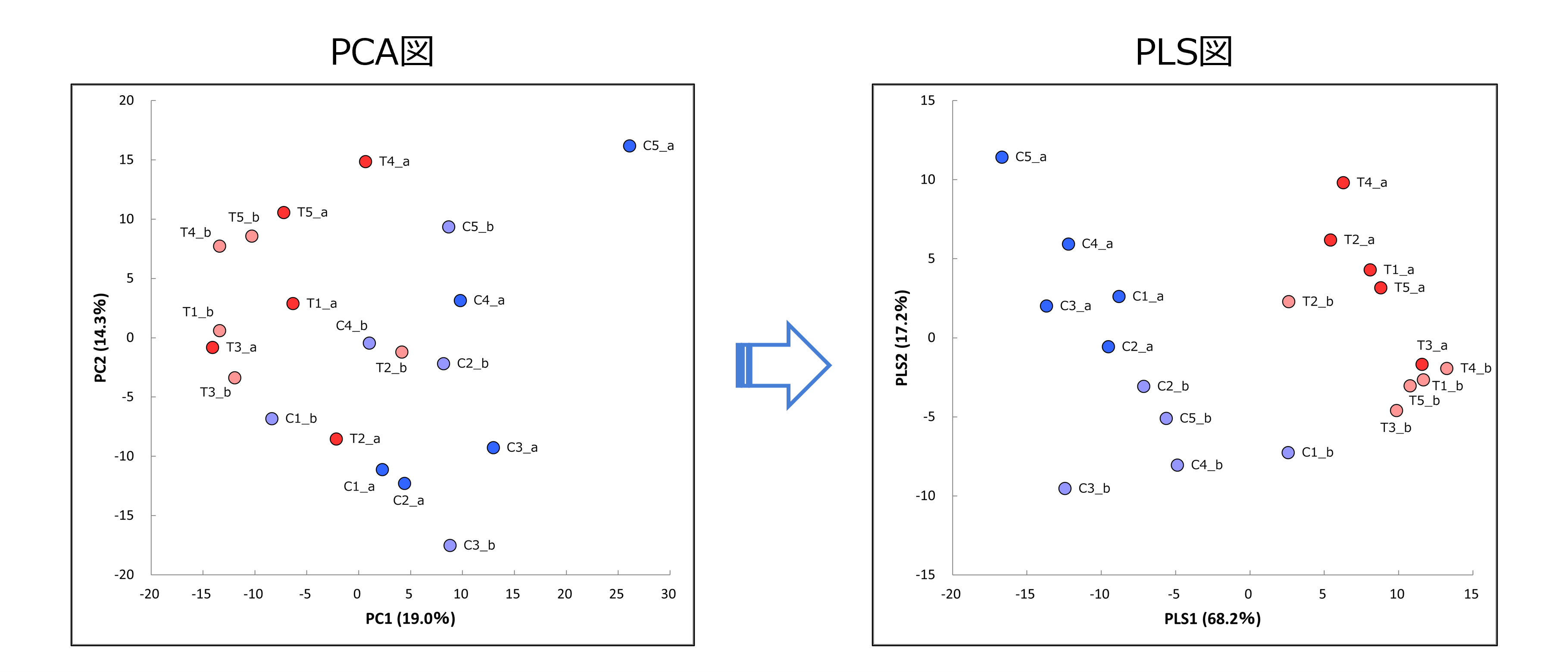
部分最小二乗法(Partial least squares, PLS)
部分最小二乗法(PLS)は、メタボロームデータの解析に汎用的に用いられる、試験群の分類情報を考慮した次元縮約を伴う多変量解析の一種です。
試験群の分類情報を考慮しない主成分分析(PCA)では群間差が不明瞭の場合に有効で、因子負荷量から各軸に相関の高い物質群を簡便に抽出できます。
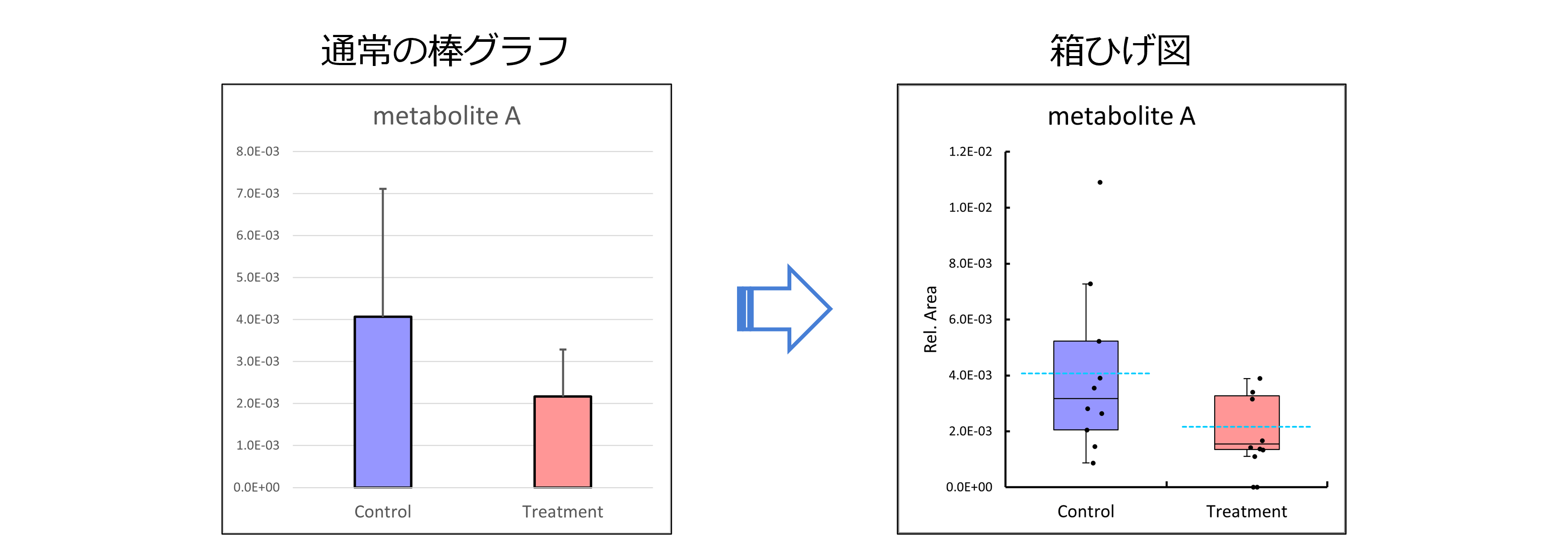
箱ひげ図(Box plot)
特に臨床検体のデータなどに関しては、各群の平均と標準偏差だけを示した棒グラフよりも、データの分布がひと目でわかる箱ひげ図(Box plot)が重宝されます。
納品されるExcelファイルには、Excelベースで作成された各物質の箱ひげ図が描画されており、フォントや色など自在に改変可能です。
論文投稿やスライドの作成に非常に便利です。
ボルケーノプロット(Volcano plot)
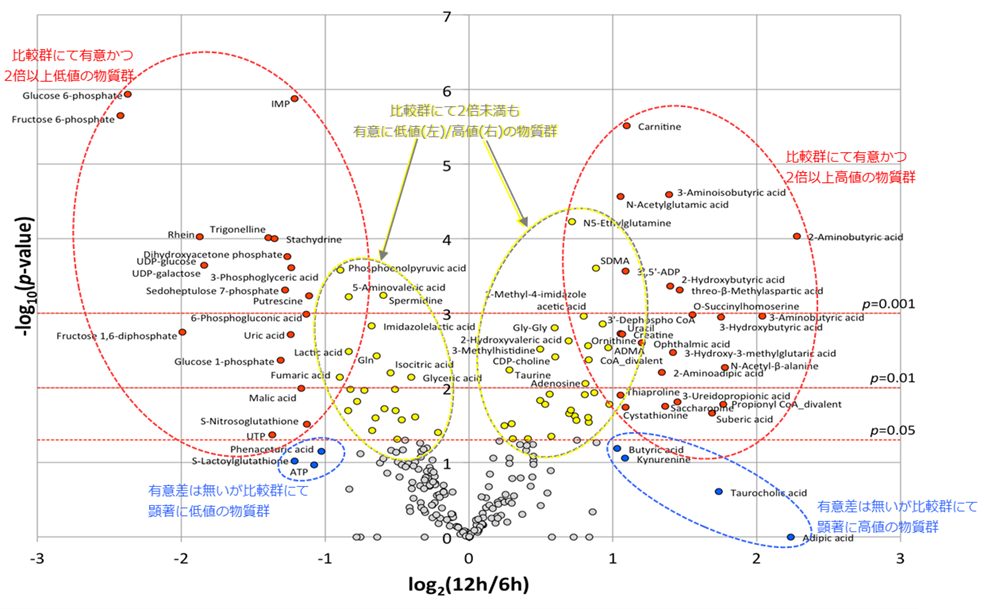
ボルケーノプロットは、それぞれの代謝物質について試験群間の比をlog2変換し横軸に、t検定結果のp値をlog10変換し縦軸に示した散布図です。
群間比較で顕著にかつ統計学的有意に高値または低値の代謝物質群をひと目で把握できます。
Metabolite Set Enrichment Analysis(MSEA)
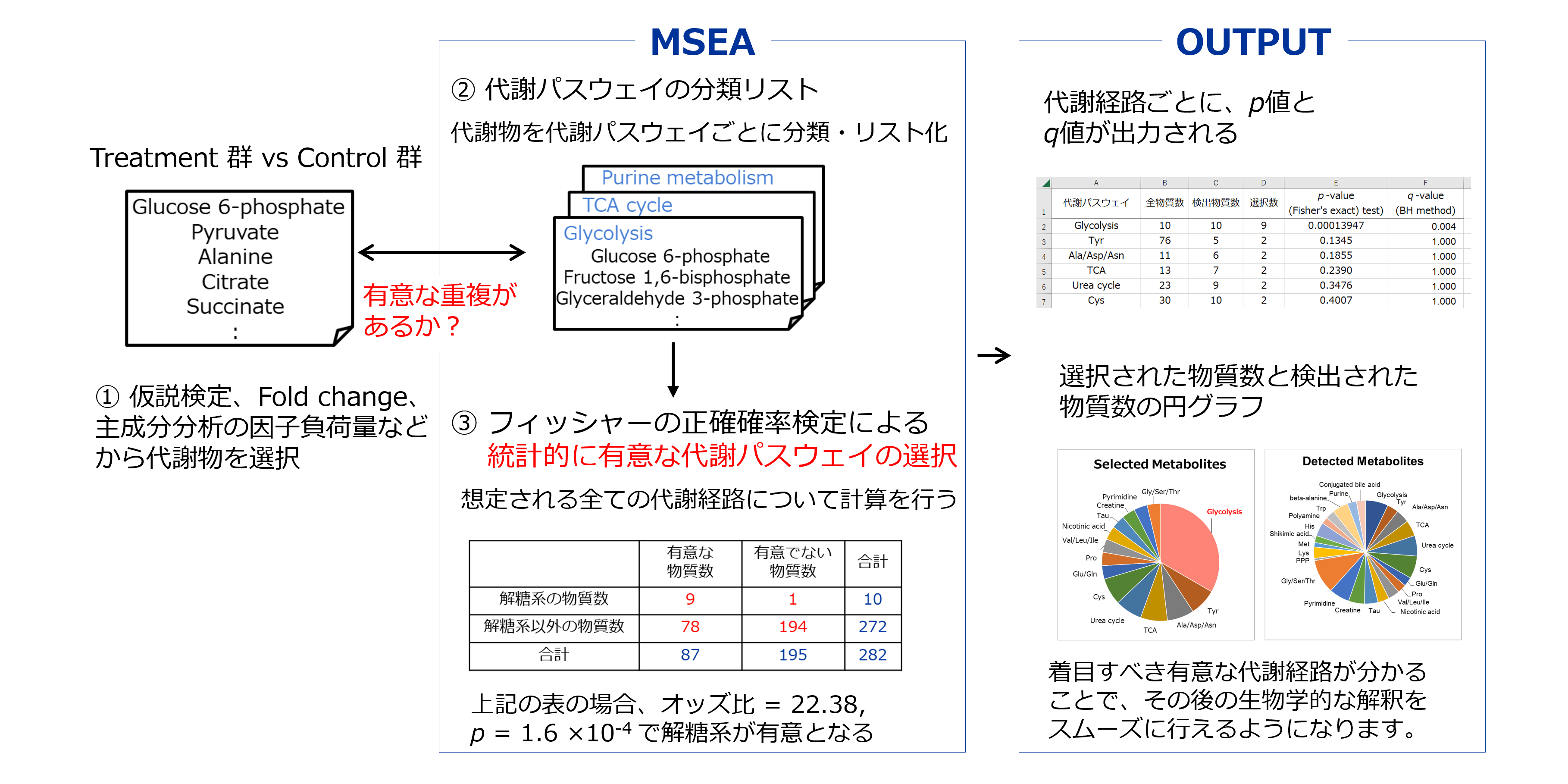
Metabolite Set Enrichment Analysis(MSEA)は、代謝物質と代謝パスウェイとの関連付けを行う解析手法です。
t検定などの仮説検定やFold changeなどをもとに差のある代謝物質を選択した上で、特定の代謝経路における選択された代謝物質数が統計的に有意かどうかを計算します。
※解析に用いる代謝経路に関しては、HMT独自の分類を用いております。
ROC曲線
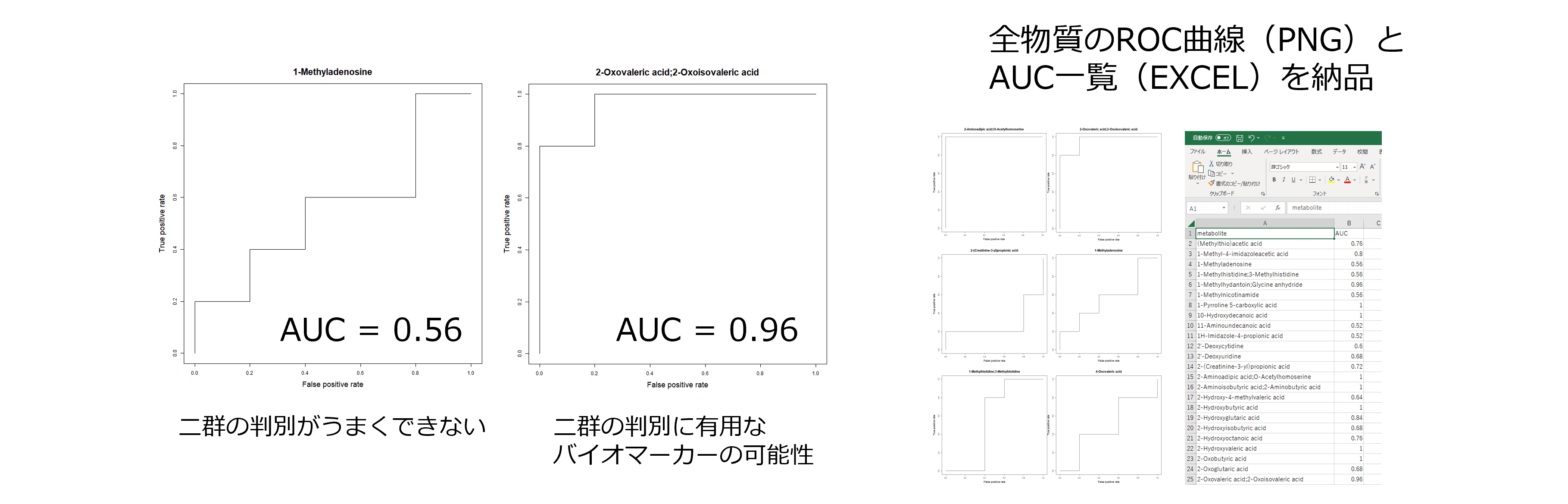
Receiver Operating Characteristic(ROC)曲線は、陽性/陰性を判別する閾値を設定した際に、縦軸に感度(真に陽性となる割合)、横軸に1-特異度(偽陽性率、陰性者を陽性と判定してしまう割合)をプロットしたものです。
ROC曲線の下部の面積をArea Under the Curve(AUC)と呼び、AUCが0.5に近い値となるほど陽性/陰性の判別がうまくいっておらず、AUCが1に近い値となるほど有効な閾値が設定されていると言えます。
代謝物ごとのAUCの値を一つの指標とすることで、有用なバイオマーカー・閾値の探索が可能となります。
ランダムフォレスト
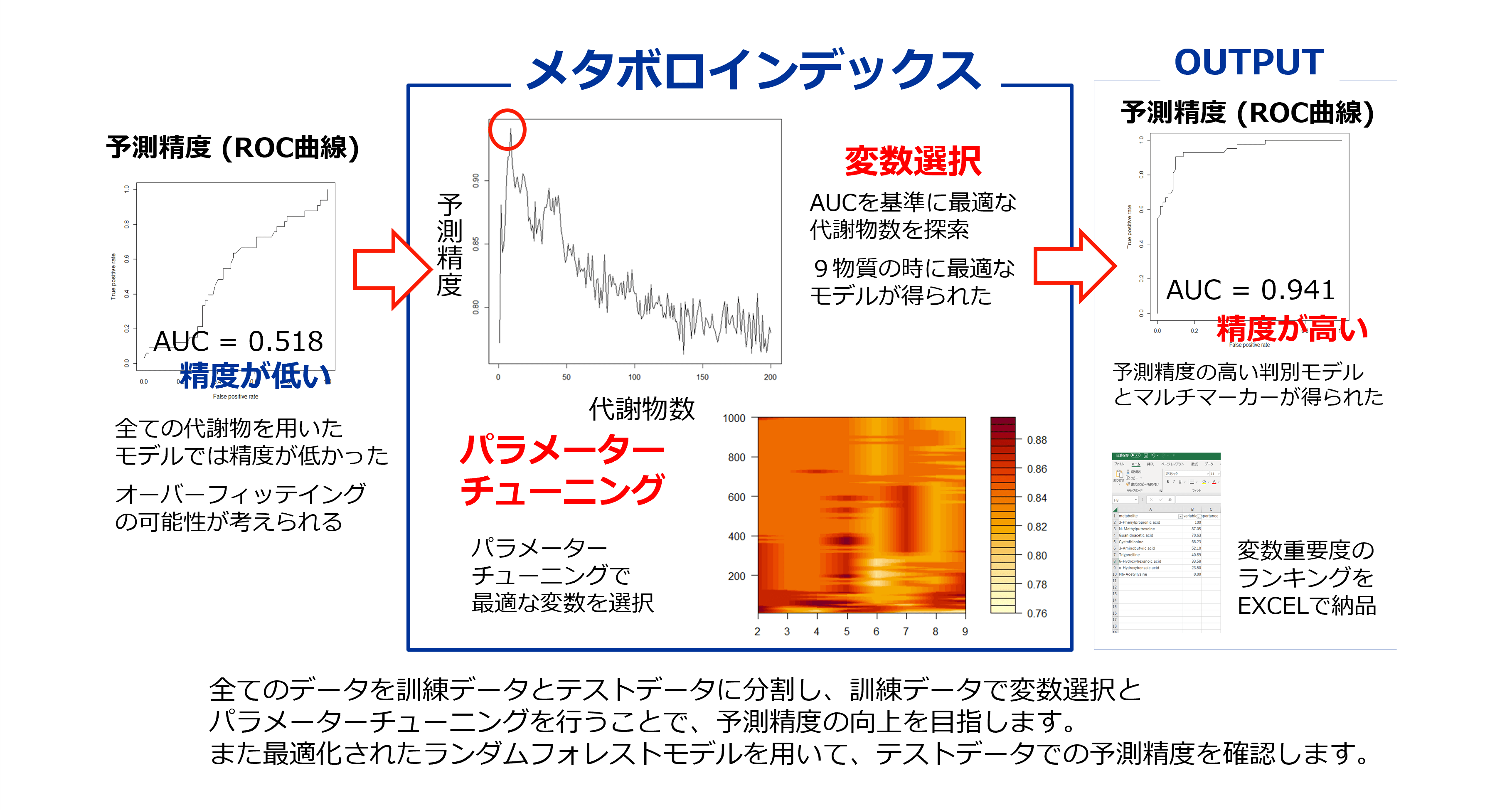
ランダムフォレストは、機械学習の分野でよく使われる分類・回帰モデルの一種で、複数のディシジョンツリー(決定木)を用いて解析を行ったうえでそれらの解析結果を学習させる(アンサンブル学習)ことにより高い精度で予測を行う手法です。
そこから得られた二群判別モデルについて、代謝物質を変数重要度順にランキングした結果を納品いたします。

ランダムフォレストを行う際に変数選択を行うことで、より少ない数の代謝物でマルチマーカー探索を行うことが可能となります。さらに、予測精度の高いマルチマーカーを得るために各種パラメーターチューニングを行います。
詳細についてはメタボロインデックスのページもご覧ください。
メタボロインデックス